
Hello, readers. Before we dive deep into ML algorithms and dataset manipulation, it is imperative to quickly go over the basics.
This is kind of a roadmap explaining the various different components of machine learning and deep learning so that you’ll have a guide to what to learn first.
Why data science?
The hype started with the Harvard business review article :
Data Scientist: The Sexiest Job of the 21st Century
Today we take the internet for granted, so let me provide some facts about today’s internet:
| people in the world | 7.77 billion |
| active Internet users | 4.54 billion |
| people using the Internet in Asia | 50.3 % of the population |
| people using the Internet in the USA | 293 million |
| average Internet user hours/day | 6.5 hours online every day |
| Internet traffic every second of the day | 88,555 GB |
| average Internet connection speed | 11.03 Mbps |
| mobile traffic every month | 40.77 exabytes |
| no. of apps in Google Play Store | 2,570,000 |
| total data in Google Search Index | 100,000,000 GB of data |
Some Internet Statistics, 2020 updated
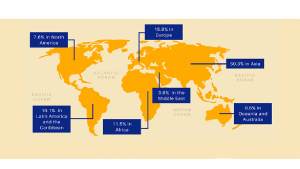
Map Of Internet Users
This is exactly the reason that data science is still a much-needed skillset.
Machine Learning – what is it?
Machine Learning (ML) is defined as a collection of computer algorithms that allow systems to learn and generate outputs autonomously and further enhance them from different analyses and outputs.
To solve market problems such as regression, sorting, forecasting, clustering, and associations, etc., machine learning algorithms can be used.
Types of ML
There are generally four types of ML algorithms:
- Supervised ML
- Unsupervised ML
- Reinforcement learning
- Semi-supervised learning
Supervised Learning
Supervised learning is a method that uses previously labelled data to learn and the algorithm predicts the unknown or potential knowledge mark.
In fact, a supervised algorithm for data science is informed of what to look for, and so it does. Until it finds the underlying patterns for the predicted output that produce a reasonable degree of accuracy.
In other words, using these previous known outputs, this machine learning algorithm learns from past data and then produces an equation for the value.
We try to model the data within supervised learning algorithms. For instance, when kaggle tells us that we need to use house price regression, then given some constraints, we model the data.
Supervised learning solves two types of problems:
- Regression (continuous target variable)
- Classification (categorical target variable)
Unsupervised Learning
Unsupervised learning is a category of machine learning algorithm that typically utilises unlabeled data to train its model.
In this method of machine learning, we allow the algorithm to self-discover the underlying patterns, connections, equations, and ties in the data without adding any bias from the user’s end (in the form of constraints / dependency).
By unsupervised learning, the secret and unknown variations in the data may be established.
And it also helps to define the characteristics that are especially beneficial for data auto-categorization.
While there is still a bit of doubt, the benefits greatly outweigh the cons.
Say you are charged with separating a bag of fruits that you have never seen. This can be summarised as follows.
So you’re likely to split them into parts depending on their physical attributes (such as weight, roughness, etc.), so even though you just divided them, you probably wouldn’t know the class titles. In unsupervised instruction, this is just what happens.
Main problems solved are:
- Clustering (for example, customer segmentation)
- Association (Market Basket Analysis)
Reinforcement learning
Reinforcement Learning consists of a part of the system, called an agent, for learning in a simulated, interactive virtual environment by trial and error.
In a reward-punishment mechanism created from feedback from their own actions and interactions, it enhances the performance.
There are no predefined labels.
Complementing the paradigm is a system of rewards for accurate responses and a system of punishments for wrong responses.
Finally, maximizing rewards is the aim of the algorithm.
But an online game called Dota 2 is an important achievement in the field of Machine Learning.
So, Elon Musk ‘s company developed an AI robot named OpenAI, which practised for an equal period of 45,000 human years against itself (reinforcement learning)! Of course, because it’s an AI, every game has been greatly accelerated.
Dota2 initially has around 115 heroes from which to pick.
After that, at any point, there is only 1 hero, with 4 skills, and a potential 6 items, each of which may have an active skill.
Multiply it with the number of players to form a team, and it is mind-boggling that the game is real-time, and the number of permutation-combinations.
Possibly, reinforcement learning is as “AI” as it comes, and it’s a highly researched subject.
Learning to strengthen addresses two broad categories of problems:
Classification (with a categorical target vector in presence) Regulation that does not have a goal (driverless vehicles, self-playing games, etc.).
Semi-supervised Learning
We also have data that is labelled with just a small portion of it, and the majority of the information is unlabeled. This is highly normal and comes under semi-supervised learning.
This is especially important because much of the data you can receive is of this sort in the real world.
This is because knowledge marking is a human activity that requires a great deal of time, commitment, and expense. Any of the data is also easier to mark.
It has a categorical target vector and functions on problems of sorting and clustering.
And that’s about it.
I like this site very much, Its a really nice post to read and incur information. Harriott Barney Jordana
Thank you for the nice comment. Do follow this as we are working on building a free course on Introductory Data Science.
Hello! I could have sworn I’ve been to this blog before but after browsing through some of the post I realized it’s new to me. Anyways, I’m definitely happy I found it and I’ll be book-marking and checking back frequently!
Hello! I could have sworn I’ve been to this blog before but after browsing through some of the post I realized it’s new to me. Anyways, I’m definitely happy I found it and I’ll be book-marking and checking back frequently!
You made some nice points there. I looked on the internet for the subject matter and found most individuals will agree with your site.