Scikit-learn for Python is a library for machine learning. It has many algorithms for regression, classification, and clustering, including SVMs, gradient boost, k-means, random forests, and DBSCAN. It is planned to work with Numpy and SciPy in Python.
As a Google Summer of Code (also known as GSoC) project by David Cournapeau, the scikit-learn project started as scikit. learn. It gets its name from a different third-party extension to SciPy, “Scikit.”
Python Scikit-learn
Scikit (most of it) is written in Python and some of its main algorithms are written for even better results in Cython.
Scikit-learn is used to construct models and, as there are better frameworks available for the purpose, it is not recommended to use it for reading, manipulating, and summarizing data.
It is open source and is licensed under BSD.
Scikit-learn (Sklearn) is the most useful and robust library for machine learning in Python.
It provides a selection of efficient tools for machine learning and statistical modeling including classification, regression, clustering, and dimensionality reduction via a consistent interface in Python. This library, which is largely written in Python, is built upon NumPy, SciPy, and Matplotlib.
Scikit-learn comes loaded with a lot of features. Here are a few of them to help you understand the spread:
- Supervised learning algorithms: Think of any supervised machine learning algorithm you might have heard about and there is a very high chance that it is part of scikit-learn. Starting from Generalized linear models (e.g Linear Regression), Support Vector Machines (SVM), Decision Trees to Bayesian methods – all of them are part of scikit-learn toolbox. The spread of machine learning algorithms is one of the big reasons for the high usage of scikit-learn. I started using scikit to solve supervised learning problems and would recommend that to people new to scikit / machine learning as well.
- Cross-validation: There are various methods to check the accuracy of supervised models on unseen data using sklearn.
- Unsupervised learning algorithms: Again there is a large spread of machine learning algorithms in the offering – starting from clustering, factor analysis, principal component analysis to unsupervised neural networks.
- Various toy datasets: This came in handy while learning scikit-learn. I had learned SAS using various academic datasets (e.g. IRIS dataset, Boston House prices dataset). Having them handy while learning a new library helped a lot.
- Feature extraction: Scikit-learn for extracting features from images and text (e.g. Bag of words)
Install Scikit Learn
Scikit assumes that you have a Python 2.7 or above framework running on your computer with NumPY (1.8.2 and above) and SciPY (0.13.3 and above) packages. We will continue with the installation once we have these packages installed.
For pip installation, in the terminal, run the following command:
pip install scikit-learn
import sklearn
Scikit Learn Loading Dataset
Let’s begin by loading a dataset with which to play.
Let’s load a straightforward dataset called Iris. It is a flower dataset and includes 150 observations of various measurements of the flower.
Using scikit-learn, let’s see how to load the dataset.
# Import scikit learn from sklearn import datasets # Load data iris= datasets.load_iris() # Print shape of data to confirm data is loaded print(iris.data.shape)
gives us: (150,4)
Scikit Learn SVM – Learning and Predicting
Now that we have the data loaded, let’s try to learn from it and predict new data. We have to construct an estimator for this reason and then call its method of fit.
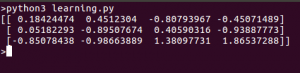
from sklearn import svm from sklearn import datasets # Load dataset iris = datasets.load_iris() clf = svm.LinearSVC() # learn from the data clf.fit(iris.data, iris.target) # predict for unseen data clf.predict([[ 5.0, 3.6, 1.3, 0.25]]) # Parameters of model can be changed by using the attributes ending with an underscore print(clf.coef_ )
Here is what we get when we run this script:
Scikit Learn Linear Regression
Creating various models is rather simple using scikit-learn. Let’s start with a simple example of regression.
Now that we have the data loaded, let’s try to learn from it and predict new data. We have to construct an estimator for this reason and then call its method of fit.
#import the model from sklearn import linear_model reg = linear_model.LinearRegression() # use it to fit a data reg.fit ([[0, 0], [1, 1], [2, 2]], [0, 1, 2]) # Let's look into the fitted data print(reg.coef_)
gives us: [0.5 0.5]
kNN
Let’s try a simple classification algorithm.
from sklearn import datasets # Load dataset iris = datasets.load_iris() # Create and fit a nearest-neighbor classifier from sklearn import neighbors knn = neighbors.KNeighborsClassifier() knn.fit(iris.data, iris.target) # Predict and print the result result=knn.predict([[0.1, 0.2, 0.3, 0.4]]) print(result)
gives us: [0]
K-means clustering
This is the simplest clustering algorithm. The set is divided into ‘k’ clusters and each observation is assigned to a cluster. This is done iteratively until the clusters converge.
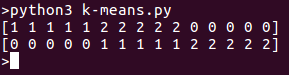
from sklearn import cluster, datasets # load data iris = datasets.load_iris() # create clusters for k=3 k=3 k_means = cluster.KMeans(k) # fit data k_means.fit(iris.data) # print results print( k_means.labels_[::10]) print( iris.target[::10])
Ending Note
If you liked reading this article and want to read more, continue to follow the site! We have a lot of interesting articles upcoming in the near future. If you are new to any of these concepts, we recommend you take up tutorials concerning these topics.